DLND项目四:基于RNN模型的机器翻译
本文是“Udacity深度学习课程项目常见问题系列”的第四篇,主要针对项目四:构建一个卷积神经网络(Recurrent Neural Network, RNN)实现机器翻译。这个项目主要基于课程第四部分第十五节:Sequence to Sequence,是seq2seq在机器翻译领域的一个应用。这个模型比较复杂,强烈推荐在做项目前,仔细阅读这个notebook,不仅有示范代码,也有大量的图示,对不少函数的作用做了解释。
text_to_ids(source_text, target_text, source_vocab_to_int, target_vocab_to_int)
- Python 的 split()函数可以指定分隔符,默认是所有whitespace,包括space, tab, newline, return等等,这里使用默认分隔符就可以了
- 也可以用Python 的list comprehension特性来简化代码
model_inputs()
- 注意data type和rank的细节
- “input”在Python里是built-in function,不要作为变量名
process_decoder_input(target_data, target_vocab_to_int, batch_size)
- 在标准的seq2seq模型中,Decoder需要不断地用前一个输出当做下一步的输入进行预测。因此,在训练阶段,Decoder的输入是目标句子的第0~(n-1)个单词,而目标输出是句子的第1~n个单词,所以需要将target_data的最后一个单词去除,在前面加上
,作用是告诉Decoder开始生成output了
encoding_layer(rnn_inputs, rnn_size, num_layers, keep_prob, source_sequence_length, source_vocab_size, encoding_embedding_size)
- 在encode layer中,我们将 LSTM cells 以及 embedded input传给tf.nn.dynamic_rnn()函数,返回enc_output, enc_state,下一步则是把enc_state传给后面的decoder
decoding_layer(dec_input, encoder_state, target_sequence_length, max_target_sequence_length, rnn_size, num_layers, target_vocab_to_int, target_vocab_size, batch_size, keep_prob, decoding_embedding_size)
- decode layer利用两个了解码器:一个用于训练,另一个用于推断(在这个例子里是翻译),这两个解码器共享权重及bias参数,这两个解码器在构造上很相似,区别在于input不同(注意下图decoder部分箭头的方向)
-
对于traning decoder来说,input 是训练集(target sequence)
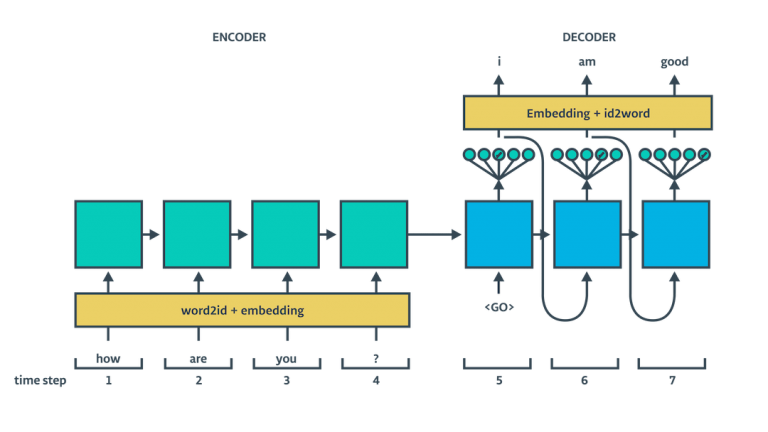
-
对于inference docoder来说,input是上一步的output
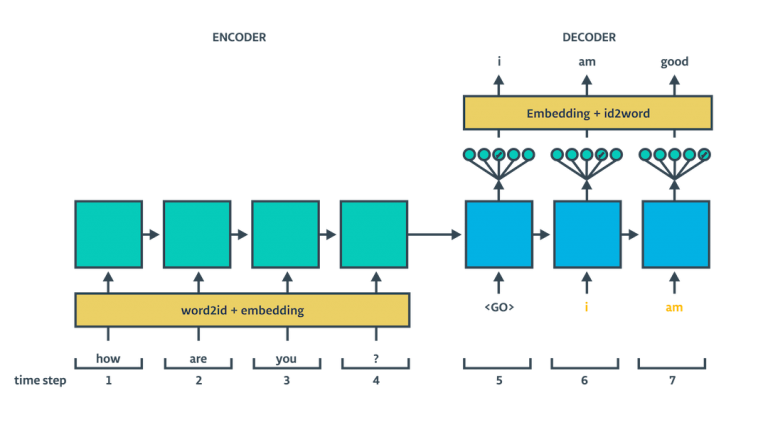
- 在构造推断函数的过程中,无需使用dropout,否则会丢掉有有用的信息。在Train这一部分计算inference_logits时,已经将keep prob设为1,确保dropout不会起作用,代码如下:
batch_train_logits = sess.run( inference_logits, {input_data: source_batch, source_sequence_length: sources_lengths, target_sequence_length: targets_lengths, keep_prob: 1.0}) batch_valid_logits = sess.run( inference_logits, {input_data: valid_sources_batch, source_sequence_length: valid_sources_lengths, target_sequence_length: valid_targets_lengths, keep_prob: 1.0})
sentence_to_seq(sentence, vocab_to_int)
- 按照要求句子需要先转换成小写形式,这是一个小问题,但可能影响你的翻译质量
- 可以用dict的get函数来简化代码,get函数能设置默认值,用法可参考[这里](https://stackoverflow.com/questions/11041405/why-dict-getkey-instead-of-dictkey)
验证或测试准确率
- 项目要求算法最终的验证或测试准确率应达到 90% 以上,这个难度不大,一个常见问题是训练的准确率跟验证准确率的差异过大,意味着存在一定过拟合。最好能保持训练准确率跟验证准确率相差不超过1%(这个是针对这个项目的经验值,不一定有普遍性)。
超参数选择
- rnn_size 是隐藏层中节点的数量,需要足够大使之能够很好的拟合数据,128或者256都是不错的选择,再大的话会增加过拟合的风险。
- embedding size 反映了对句子做encode以及decode时获得的信息的量,一般跟词汇量对应,建议200左右
- 给定其他参数,如果较小的epochs已经达到了比较好的效果,或者准确率不再明显下降,就没有必要增加epoch了。根据经验,这个项目不超过10个epoch就有不错的效果
- learning_rate 不能太大,如果太大的话那么训练算法将不会收敛。不过也要是适当的值,确保算法不会无限制地训练。