DLND项目二:构建CNN模型为图片分类
本文是“Udacity深度学习课程项目常见问题系列”的第二篇,主要针对第二个项目:构建一个卷积神经网络(CNN)对图片进行分类。通过这个项目,学员可以学习CNN的基本知识,以及tensorflow的常见模块和概念,比如placoholder、tensor、graph等等。
normalize(x)
x的范围是0-255,虽然有256种可能的取值,但标准化(normalize)的话,应该除255而非256x的类型已经是np array,不用再利用np.array()对x进行转化- Python3
/运算符直接返回float类型的值, 即1/2=0.5
one_hot_encode(x)
- 项目要求”调用 one_hot_encode 时,对于每个值,one_hot 编码函数应该返回相同的编码。确保将编码映射保存到该函数外面“,意思是将编码映射(mapping)保存在
one_hot_encode(x)函数外,这样每次调用该函数的时候,不用每次都定义新的mapping - 项目提示“不要重复发明轮子”,可以利用已有的函数创建编码,比如:
conv2d_maxpool(x_tensor, conv_num_outputs, conv_ksize, conv_strides, pool_ksize, pool_strides)
- 使用
tf.truncated_normal初始化权重时,要让初始化值在一个相对较小的范围变动,因此要限定标准差stddev。tf.truncated_normal默认的标准差是1,在这个项目中显得过大,可以尝试0.05或者0.1 - 初始化权重已经引入了随机性,因此可以将bias初始化为0,无需初始化为随机值
-
‘SAME’和‘VALID’的差异:Stackoverflow上有一个很好的答复(作者MiniQuark),这里翻译介绍如下:
基本假设: Input width = 13,Filter width = 6, Stride = 5
“VALID”意味着放弃最后两个值,得到两个大小为6的filter
"VALID" = without padding: inputs: 1 2 3 4 5 6 7 8 9 10 11 (12 13) |________________| dropped |_________________|“SAME”意味着尽量按照左右对称的方式补齐,如果要补齐的数量为奇数,多出来的一个补在右边。最后得到的是三个大小为6的filter
"SAME" = with zero padding: pad| |pad inputs: 0 |1 2 3 4 5 6 7 8 9 10 11 12 13|0 0 |________________| |_________________| |________________|
fully_conn(x_tensor, num_outputs)
- 可以调用现成的函数,比如
tf.contrib.layers.fully_connected()或者tf.layers.dense, 也可以自己执行 - 如果自己执行的话,初始化权重的方式类似于
conv2d_maxpool
output(x_tensor, num_outputs)
- 同上,可以调用现成的函数,也可以自己执行
- 如果使用
tf.contrib.layers.fully_connected(),要明确将激活函数设为None, 因为这个函数默认使用ReLU非线性激活函数,而这里已经到了输出层,不需要非线性激活。如果使用tf.layers.dense,默认不使用激活函数 - 如果自己执行的话,初始化权重的方式类似于
conv2d_maxpool
conv_net(x, keep_prob)
- 为更好的理解各个部分之间的关系,建议把这段课程视频多看几遍以理解CNN的基本原理,这里是一个截图
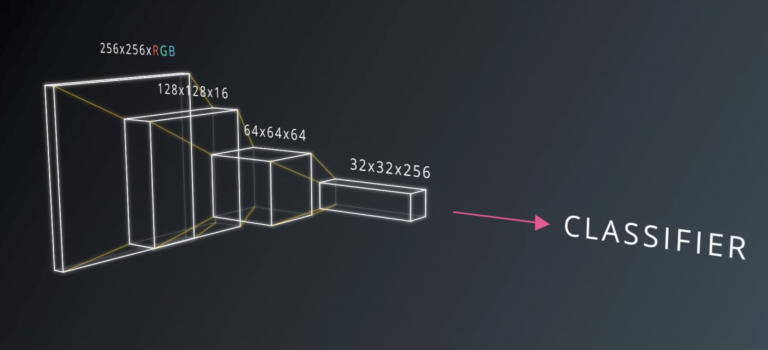
- 强烈推荐阅读Stanford cs231n 有关卷积神经网络的笔记,将convNet的核心部分做了极好的综述
- 推荐在全连阶层(fully_conn)使用Dropout技术来减少过拟合(overfitting),因为conv2d_maxpool层本身通过减少节点数量,起到一定控制过拟合的作用
- conv2d_maxpool的层数不宜过少,否则无法有效对图片信息进行表征。对这个项目来说三层比较合适,可以逐步调大
conv_num_outputs的值(比如32->64->128)
print_stats(session, feature_batch, label_batch, cost, accuracy)
- 在计算validation准确率的时候,需要使用之前定义的全局变量(验证集数据):valid_features 以及 valid_labels,而计算 training loss的时候需要使用训练集数据:feature_batch和label_batch。
参数选择
- batch_size: 一般设为64、128、256、512等等,通常较大的batch_size效果较好,但过大的size会导致模型一般化的能力较差,这里有个讨论可以借鉴
- epochs:数目并不是越大越好,如果模型的loss值或者验证准确率区域稳定,不再有明显下降,就可以停止训练了。